Have Data Centers Raised Your Electric Bill? Causal Evidence from the United States [shows the opposite]
![Have Data Centers Raised Your Electric Bill? Causal Evidence from the United States [shows the opposite]](https://external-preview.redd.it/q3evP6JeDpAC2MdSQHWYxnCYTqbJkElIQsLFqVSdkss.png?width=640&crop=smart&auto=webp&s=de730fbf7ecace6df0036b21470c16a2d4feacfb)
arxiv.org
SUMMARYAlan Turing developed a working model of Delilah, a portable voice encryption device, during research at Hanslope Park after drawing inspiration from German cipher systems broken at Bletchley Park. His private papers show he demonstrated the machine with a Winston Churchill speech recording, and the device weighed 39 kilograms including its power pack. The project ended after World War II because it was no longer needed, not because it failed.
Long-time Slashdot reader smooth wombat writes: Alan Turing, one of the more famous people who worked at Bletchley Park to decipher the German Enigma coding machine, was also working on a separate project. His private papers, known as the Bayley papers for his assistant Donald Bayley who held onto the papers until his death in 2020, reveal Turning had produced a working model of a portable voice encryption device. He even demonstrated it by using a Winston Churchill speech recording. "Weighing just 39 kg, including its power pack," Jack Copeland wrote in an article for IEEE Spectrum, "Delilah would be at home in a truck, a trench, or a large backpack."
More from Popular Mechanics:
Turingâ(TM)s work at Bletchley Park actually informed the Delilah experimentation he was doing at Hanslope Park, and not just because he used Red Forms, the Army-issue sheets Hanslope staffers were meant to use to alert Bletchley staffers to enemy signals, as his personal scrap paper for Delilah experiments. He drew inspiration from one of the German cipher machines they had decoded at Bletchley; not the famed Enigma machine, but rather the SZ42. While the former relied on Morse Code, the latter utilized a 5-bit telegraph code, which Copeland notes âoewas a forerunner of ASCII and Unicode and is still used by some ham radio operators.â The SZ42 produced an obscuring key of telegraph characters, with an identical key produced to both the sender and receiver. If it could be done for text, Turing reasoned it could be done for sound as well...
[T]he reason Delilah fell to the wayside of history isnâ(TM)t because it was a failure, but rather because it simply wasnâ(TM)t needed anymore. By the time Turing had built and demonstrated his device, the war was over. What good was a portable voice encryptor if you had no major enemies trying to intercept your calls, the government reasoned. So funding for the project stopped, and Turingâ(TM)s two-year experiment ended with a whimper. Turingâ(TM)s time as an electrical engineer at Hanslope Park became a footnote in his story, if even that.

forbes.com

gsb.stanford.edu
SUMMARYRobert Cringely co-founded 2Brains Inc. with two partners in 2022 to reduce large language model hallucinations using an architectural approach rather than scaling up models. The system separates language generation from fact retrieval and verification, runs on ordinary processors, and the company claims it beats the published baseline on a faithfulness benchmark without fabricated facts in verified cases.
Long-time tech pundit Robert Cringely started his career at the Stanford Artificial Intelligence Lab back in 1978. Last month 73-year-old Cringely explained why his site went on a two-year hiatus - and it's not just because of a heart attack and a stroke last July:
Just like everyone else, I've been busy all this time on Artificial Intelligence, founding with two partners a company called 2Brains... The work we were doing together is unfinished, but it's not stopped. The patents are filed, the architecture is documented, and the small team continuing the work includes me.
Cringely's first piece made the cast that "the trillion-dollar bet the AI industry is making right now may be wrong, and that there's an architectural alternative we've patented and built."
In Machines of Loving Grace, Amodei made the case that scaling compute would eventually solve essentially every hard problem in artificial intelligence. Buried in that optimism - or maybe not buried, maybe right out in the open - was a quiet absolution. Hallucinations, the embarrassing tendency of these systems to state falsehoods with total confidence, would take care of themselves. Make the models big enough, train them long enough, and the problem dissolves. You don't have to solve it. You just have to wait, and spend. And so the entire AI industry breathed a sigh of relief.
I have spent forty years watching this industry, and I know a permission slip when I see one.
Because that is what the essay became, whatever Amodei intended. It gave every other person writing nine- and ten-figure checks a reason not to worry about the one thing that should worry them most. The hallucination problem is the difference between a clever toy and a system a hospital or a bank or a court can actually rely on. It is the whole ballgame for enterprise AI. And the prevailing wisdom, blessed from the top, is that you needn't address it directly. Scale will provide...
A small company I helped start, 2Brains Inc., set out in 2022 to solve hallucinations - before ChatGPT, before the scaling consensus hardened into received truth, back when the polite assumption was that the problem was simply insurmountable. We did not solve it by waiting for bigger models. We solved it architecturally, by separating the part of the system that generates language from the part that retrieves and verifies facts, and reconciling the two before anything reaches the user. It runs on ordinary processors. It is cheap. And on the industry's own benchmark for this kind of faithfulness, it more than doubles the published baseline, with no fabricated facts in the verified case at all.
The article asks whether scaling will, at tremendous cost, eventually reduce hallucinations - or even worse, if the largest companies in the world "are spending a fortune chasing a cure that is not coming."
And last week Cringely pitched more advantages for their solution, noting that most prompts aren't even chatbot-level creative prompts - but just requests to retrieve simple data:
The reason 2Brains doesn't lie and the reason it's cheap are the same reason. It looks the fact up instead of guessing it - so it cannot fabricate, and the lookup runs on a processor that sips power instead of a chip that gulps it. Trust and thrift are not a trade-off you balance against each other. They fall out of a single design decision. You do not pay extra for the honest version. The honest version is the cheap version. That sentence is the whole company.

Image: Cath Virginia / The Verge
Atlantic reporter Alex Reisner recently uncovered four datasets of music being used to train AI models and made them fully searchable for the public. Two of the sets are absolutely enormous at 12 million and 9 million tracks. The other two are much smaller, but still represent a significant amount of training data at over 100,000 songs each.
According to Reisner, the sets have been downloaded thousands of times and, while it's impossible to know exactly who has used them, Google and Stability have both confirmed they have in research papers. Some of the sources, like the Free Music Archive dataset, are free to stream for personal use but re …
Jumper isn't the only big name leaving Google DeepMind.
SUMMARYThe Society of Motion Picture and Television Engineers has made its entire standards catalog free to access, including published standards, recommended practices, engineering guidelines, registered disclosure documents, and future releases. The move removes a long-running paywall on documents that define key media technologies such as SDI, timecode, and ST 2110, and it comes alongside a modernization effort using GitHub workflows, structured HTML authoring, and an integrated publishing pipeline.
The Society of Motion Picture and Television Engineers has published over 800 technical standards over the years (as a professional association for the media and entertainment industry).
But this week SMPTE "announced that its complete Standards catalog, the technical backbone behind everything from SDI and timecode to IP-based broadcast workflows, is now freely available to anyone in the global media technology community," reports the filmmaking news site CineD, arguing it's "one of the more meaningful structural shifts we have seen from a standards body in years" that could "reshape how smaller developers and educators engage with professional media technology."
The move covers all published Standards, Recommended Practices, Engineering Guidelines and Registered Disclosure Documents, plus every future release, ending a long-standing model in which individual documents often sold for well over $100 each. For more than a century, SMPTE Standards have quietly governed how images and sound move through the production chain. If you have ever recorded timecode in the HH:MM:SS:FF format, routed a signal over 3G-SDI, or built a facility around the ST 2110 suite for media over IP, you have relied on SMPTE specifications, whether you knew it or not... Until now, accessing the actual text of those documents usually meant paying per file, a barrier that this announcement removes entirely... The latest releases are available through the Recently Published Documents page on the SMPTE website, with the complete archive reachable through the SMPTE Standards Library...
There is also a practical, behind-the-scenes story here. The open-access move is part of a broader modernization of how SMPTE develops and publishes Standards. Recent initiatives include adopting GitHub-based workflows for version control, issue tracking and automation, transitioning to structured HTML-based authoring, and implementing an integrated publishing pipeline that streamlines document creation, review, validation and release... The most consequential beneficiaries are arguably not the large members already inside the system, but the developers, integrators, educators and manufacturers who previously worked around the paywall... The practical upshot is that developers and emerging markets can build from accurate primary specifications rather than secondhand sources, which matters enormously when a single misread tolerance or metadata field can break compatibility down the line.
This also fits a wider pattern of the industry moving toward openness. We have previously covered moments like GoPro's decision to make its CineForm codec open source and release the SDK, a codec that SMPTE itself standardized in 2015 as an open standard for acquisition and post production. Lowering the cost of knowledge tends to widen the pool of people who can contribute to it, and a freely readable standards library is a significant step in that direction for an organization that has historically sat behind a per-document fee.
"This was a decision we did not make lightly," says SMPTE President Rich Welsh. But "For 110 years, SMPTE has evolved alongside the media technology industry, helping to drive change and innovation - and we're not stopping now."
"Our industry is confronting transformative shifts, from IP-based workflows to AI authenticity and content provenance, and we find ourselves at another inflection point. We listened to our Members, Partners and the global Standards community, and the answer was clear: Interoperability is essential to the future of media. Now is the time to open the gates and ensure the next generation of media technology is built on a stronger, more accessible foundation."
Thanks to innocent_white_lamb (Slashdot reader #151,825) for sharing the news.
aiweekly.co
aiweekly.co
Colon cancer’s invisibility cloak removed by eliminating a single gene - a fundamental breakthrough. The result was 100% eradication of tumours when paired with immunotherapy treatment in mouse models.

ucalgary.ca
SUMMARYThe Free Software Foundation patched vulnerabilities in GNU Savannah after security researchers from Hacktron.AI found and demonstrated an exploit in early May. FSF said the issues affected software published about two years earlier, that no evidence showed sensitive data or supply-chain compromise, and that additional precautionary steps and notices to hosted projects and other Savane instances are underway.
The Free Software Foundation's GNU Savannah hosts thousands of free software projects - both GNU and non-GNU projects, including Drupal.
But in early May, security researchers from Hacktron.AI reported vulnerabilities and demonstrated an exploit, according to a new statement Friday from the FSF:
We have been working with these researchers since their initial report, and have also addressed additional security issues they submitted. All reported issues have been patched thanks to the hard work of GNU and FSF volunteers, as well as FSF staff. After thorough review, we have found no reason to believe that sensitive project data or credentials were accessed, nor that there has been any compromise of Savannah's software supply chain.
Nevertheless, we take the security of the GNU system, the tools which make it possible, and the projects we host very seriously. This body of software has become essential to millions (if not billions) of users around the world. We are therefore taking additional precautionary steps. Though the initial security issue was reported to us in early May, the vulnerabilities were discovered in software that was published approximately two years prior. We will be communicating directly with Savannah-hosted projects about steps they can take to review and strengthen the security of their projects. We have also communicated with the other Savane instances we're aware of to assist their review of their own environments, and take any steps needed to help protect their users... This statement is intended as an initial notice. We expect to publish a report on the incident within 30 days.
Hacktron.AI bills itself as "Your AI teammate for security." Its web page notes that its investors include Meta, DeepMind, and Perplexity.

sciencedaily.com

spectrum.ieee.org
spectrum.ieee.org
Orbital upmass is growing so fast that the naive trendline has us disassembling Earth by 2144 - Dr. Alex Wissner-Gross
For the first time in history, researchers have used AI to collect, OCR, process, and create a database of every single law in America. 2.2 million laws. "LocalLaws/LOCUS-v1 · Datasets at Hugging Face" If history is any guide, radical transparency often leads to radical change.

huggingface.co
arxiv.org

ibm.com
SUMMARYResearchers developed an ultrasonic espresso process that uses high-frequency sound waves to extract coffee flavor at room temperature, producing espresso-strength coffee in under three minutes. The method can cut brewing energy use by up to 75% by avoiding water heating, and taste tests found drinkers could not reliably distinguish it from traditional espresso. The process could help industrial coffee makers produce concentrates for bottled drinks, milk beverages, and cold coffee products.
Researchers developed an ultrasonic espresso process that uses high-frequency sound waves instead of hot water to produce espresso-strength coffee at room temperature. And, not only did coffee drinkers find it comparable to traditional espresso, but the brewing process cut energy use by up to 75%. An anonymous reader quotes a report from The Conversation: We have developed what we call an ultrasonic espresso: a room-temperature brewing process that uses high-frequency sound waves to extract the flavor, oils, aroma and caffeine from coffee grounds. The result is an espresso-strength coffee made in under three minutes, but needing far less energy than the conventional method. Saving up to 75% of energy by not heating the water is a minor benefit for home users or small coffee shops. But for companies making ready-to-drink coffee products at industrial scale, it could be very significant indeed. A concentrated room-temperature coffee could be used directly in bottled drinks, milk-based beverages or cold coffee products. It can also be shipped as a concentrate and diluted later. This would reduce not only energy use, but potentially processing time as well.
The key to the new process is ultrasound. These are sound waves above the range of human hearing. In our system, a small metal device called a transducer presses against the side of a traditional espresso basket and makes it vibrate rapidly. Those vibrations move through the water and coffee grounds. This creates a phenomenon known as acoustic cavitation. Tiny bubbles form and collapse in the liquid. When these bubbles collapse near coffee particles, they produce microscopic jets and forces that act a little like scrubbing brushes. They pit and fracture the surface of the coffee grounds, helping flavor compounds, oils and caffeine move into the water much faster than they normally would at room temperature. In other words, ultrasound helps us replace heat with mechanical energy.
[...] In earlier work, we used ultrasound to speed up cold brew dramatically. But the challenge in this project was different: could we produce something with the strength, body and intensity of espresso, without heating the water? To do that, we adjusted several variables. Brew ratio was one of the most important: how much water we used for each gram of coffee. Too much water and the drink becomes diluted; too little and extraction becomes difficult. Grind size also mattered. Finer grounds allowed us to extract flavor more rapidly. Finally, we tested how long the ultrasound should be applied. We found the sweet spot was about two-and-a-half to three minutes. Of course, making a concentrated coffee in the laboratory is one thing. The real test is whether people want to drink it. [...] For the espresso samples, participants could not reliably tell the traditional and ultrasonic versions apart. There were no significant differences in aroma, flavor, bitterness or overall liking. For filter coffee, the ultrasound version was actually preferred overall, with participants rating its bitterness more pleasantly.
Researchers introduce T-Rex, a framework that unifies vision, language, and tactile sensing so robots can respond to physical contact in real time rather than relying on vision alone
@OpenAINewsroom "For families facing rare genetic diseases, answers can be hard to find. @HallieJackson spoke live with @_perloj and Dr. Catherine Brownstein about the new NEJM AI paper and our work with Boston Children’s Hospital, where experts used o3 Deep Research to help diagnose rare"

"Global #GaussianSplatting rendering in the browser. Inspect a splat in full detail — then zoom all the way out to #Space. This is running in @arrival_space_ with our new Cesium/Google tile renderer, atmospheric simulation, and time-of-day lighting. Demo 🔗↓"
nature.com
nature.com
"I think many people still underestimate the full implications of China potentially gaining access to ASML-level EUV technology. The supply chain currently works like this: -ZEISS in Germany produces the ultra-precise optics and mirrors that are essential for ASML’s lithography"


bloomberg.com
Another outstanding point by Perry. People always blame technology, but the problem is people and human institutions. If technology reveals flaws in imperfect institutions, then that's a good thing, and will provide the impetus for positive change.

SUMMARYHyundai Motor Group is buying SoftBank’s remaining 9.65% stake in Boston Dynamics for $325 million, making the Waltham, Massachusetts robotics company a wholly owned Hyundai subsidiary. SoftBank previously sold Boston Dynamics to Hyundai in 2021, after acquiring it from Alphabet in 2017. Hyundai and Boston Dynamics also showed an electric Atlas humanoid robot at CES in Las Vegas on January 5, 2026, and a production version is expected to begin work at Hyundai’s EV plant near Savannah, Georgia, by 2028.
Hyundai Motor Group is acquiring SoftBank's remaining 9.65% stake in Boston Dynamics for $325 million, "closing out SoftBank's last piece of Boston Dynamics and turning the Waltham, Massachusetts robotics company into a wholly owned Hyundai business," reports Startup Fortune. From the report: The price is $325 million for the remaining stake, according to the deal terms, and it follows the put option SoftBank retained when Hyundai bought control of Boston Dynamics in 2021. You should read that as a signal, not a footnote. Hyundai paid about $880 million for an 80% stake in Boston Dynamics in the 2021 transaction, valuing the company at roughly $1.1 billion at the time. SoftBank had bought Boston Dynamics from Alphabet in 2017, after Google had acquired the robotics lab in 2013. It was a strange ownership path for a company whose robots became famous on YouTube long before they became obvious commercial products.
That part is changing. At CES in Las Vegas on January 5, 2026, Hyundai and Boston Dynamics showed the electric Atlas humanoid robot in public, with the Associated Press reporting that the life-sized robot stood up, walked around the stage and was remotely piloted for the demonstration. The useful detail was not the stagecraft. It was the deployment plan. A production version of Atlas is expected to begin work at Hyundai's electric vehicle plant near Savannah, Georgia, by 2028. [...] If Hyundai can turn that into repeatable manufacturing value, the SoftBank exit will look less like a tidy cleanup and more like the moment Hyundai stopped borrowing a robotics future and decided to own it outright.

Image: Alexander Tamargo / Getty Images
Relativity Space, the rocket company led by former Google executive Eric Schmidt, was picked to launch NASA's Aeolus payload to Mars in 2028, as reported earlier by TechCrunch. Under a new public-private partnership, Relativity Space will provide the "spacecraft, rocket, and cruise operations" to fly Aeolus to Mars, where the payload will "provide the first integrated, daily, global view of Martian winds, temperatures, dust, and clouds."
The Aeolus payload will have four instruments on board for studying the Martian atmosphere, which NASA says will "directly inform entry, descent, and landing systems and support safer, more predictable mis …
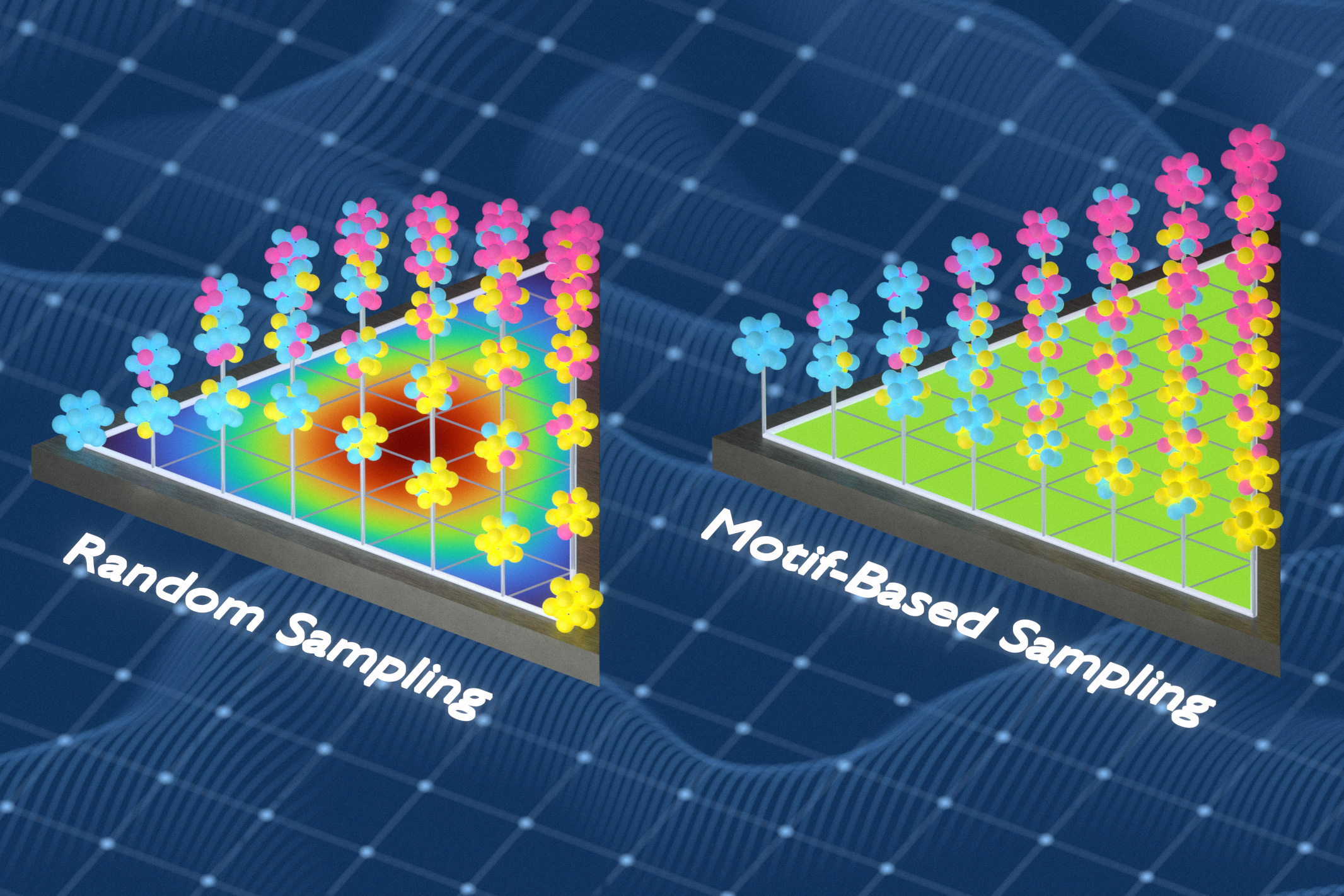
SUMMARYMIT researchers developed a machine-learning technique that better models chemically disordered metal alloys by building training datasets that capture a wider range of local atomic environments. In tests on diverse alloys, the method predicted material properties and phase diagrams more accurately than random sampling and other common approaches, with potential applications in aerospace, energy, computing, and the design of stronger, more damage-tolerant materials.
Credit: Courtesy of the researchers
news.mit.eduCompanies working at the frontier of aerospace, energy, and computing are constantly looking for new materials to improve performance. But in order to understand how those materials will actually behave once they’re inside rockets or on computer chips, companies first have to make the material and then test it. That’s because even the most powerful simulation techniques struggle to model the complex chemical arrangements in most of today’s solid materials. The problem adds costs and time to materials innovation.
Now a team of MIT researchers has created a way to accurately model the behavior of metals, regardless of the complexity of their chemical arrangement. At the center of the approach are machine-learning models that make simulations of materials faster and more accurate. The researchers improved those models by building training datasets that capture the diversity of atomic environments in chemically disordered materials.
In a new paper in Sciences Advances, the researchers showed their approach could be used to accurately predict material properties for a diverse group of metal alloys under a range of conditions. They also showed how the approach could be used to develop new materials, especially in scenarios where experimentation is expensive.
“The focus of the paper is metallic alloys, which is the field I work in, but this could be adapted to other types of materials, like semiconductors,” says senior author Rodrigo Freitas, MIT’s TDK Career Development Professor in Materials Science and Engineering. “This is not specific to any one application — you could use this approach to create new sustainable steels, new materials for aerospace, and more. That’s what makes this exciting.”
Joining Freitas on the paper are first author Killian Sheriff PhD ’26; MIT PhD students Daniel Xiao and Yifan Cao; and University of Sheffield Senior Lecturer Lewis R. Owen.
Modeling metals
Material properties are mostly determined by the internal arrangement of their chemical elements. Even if two materials have the same mix of chemical elements, different chemical arrangements can make the difference between a brittle material and one that deforms without breaking.
Capturing that distinction requires simulating materials atom by atom. To do that, researchers rely on models that describe how atoms interact with each other. Over the last two decades, machine learning has become the most accurate way to build those models. Such models work well when the chemical arrangements inside materials follow highly ordered patterns, but that’s not the case with most solid materials, whose atomic chemical arrangements are disordered and vary from one region to another.
“The real challenge in our field is modelling these chemically disordered phases,” Freitas says. “Chemical disorder means there’s a huge variety of local chemical environments, which is hard for the machine-learning model to learn. This is a problem because every single metal we use in practice is chemically disordered.”
The problem comes down to a lack of representative training data for those atom-by-atom simulations. The current leading approach for creating such data works by brute force, often requiring more than 100,000 hours of computation to create the training data for a single material. Even then, it does not transfer well when researchers change the material’s composition.
In previous work, Freitas’ group had developed a way to measure the chemical complexity of solid materials by analyzing the frequency and spacing of tiny groups of atoms. For this study, the researchers used that capability to build better training datasets. They used a mathematical approach known as information theory to generate training datasets that capture a wider variety of local chemical environments inside disordered materials. The method works by swapping out atoms from samples to reduce repetition and expose the model to chemical environments it might otherwise miss.
“We kept optimizing the training set so it captured as many different local environments as possible,” Freitas says. “If the same kind of environment showed up many times, we replaced redundant examples with ones the model hadn’t seen before. That makes the training set much more informative because each example adds something new.”
When trained on the researchers’ datasets, the models predicted material properties more accurately than models trained using random sampling or another popular sampling method.
“The starting point for all these atom-by-atom simulations is: Are you able to accurately describe the chemical bond between atoms?” Freitas explains. “If not, it can still teach you about materials in general, but it doesn’t tell you what will happen to specific materials in the real world. This approach makes the simulations high fidelity in terms of their chemistry, to better reflect what’s happening to materials.”
The researchers applied their technique to create machine-learning training datasets for a group of chemically diverse metal alloys. Using a set of machine-learning models, they showed the models trained on their datasets are more accurate than much larger models created by companies like Google and Microsoft.
“We got to a point where we were convinced it worked without using these expensive brute-force methods,” Freitas says. “I told Killian, ‘This is a good paper. But if you can show that simulations with these models can now accurately predict useful materials properties, then it becomes a very good paper.’ Killian took that to heart and tested this as widely as he could.”
Sheriff worked with Xiao and Cao to test the approach across different alloys and properties. The team also drew on Owen’s experimental data to compare the simulations against real measurements of atomic ordering in alloys.
From the lab to industry
The method works, in part, by capturing hidden patterns in the sample data. The researchers describe the patterns in the paper as “subtle energetic biases toward certain local chemical configurations.”
Those small energetic differences matter because they determine which phases form in an alloy, how those phases change with temperature and composition, and ultimately which properties the material will have. As one test, Daniel Xiao led simulations showing that the team’s models could predict phase diagrams that closely matched experimental data. Phase diagrams map which phases are stable across different temperatures and chemical compositions, and they are a central tool for designing and processing alloys.
“Phase diagrams are one of the main ways people connect materials modeling to real processing decisions,” Freitas says. “If you are welding, casting, or heat-treating an alloy, you need to know which phases are likely to form under different conditions. Our goal is to make these kinds of predictions accurate enough, and accessible enough, that they become part of how people design materials.”
The researchers are now using the approach to study how changing an alloy’s composition affects mechanical properties and radiation tolerance, with the goal of designing materials that remain strong and damage-tolerant in harsh environments. They are also working to make the method easier to use with the kinds of tools and workflows materials engineers already rely on.
“Industry isn’t going to change the way they do things if what you’re creating doesn’t fit into their existing operating procedures,” Freitas says. “The goal is to make these predictions useful in the places where materials decisions are actually made.”
The research was supported by the U.S. Air Force Office of Scientific Research.
In the span of 3 days: Noam Shazeer (Transformer co-author) leaves Google for OpenAI, and John Jumper (Nobel laureate, AlphaFold lead) leaves Google DeepMind for Anthropic

Reliance is weaving AI into telecom services used by more than 500 million people.
Sanders unveils American AI Sovereign Wealth Fund Act, aims for $1,000 annual payments for US citizens

interestingengineering.com

This is Optimizer, a weekly newsletter sent from Verge senior reviewer Victoria Song that dissects and discusses the latest gizmos and potions that swear they're going to change your life. Opt in for Optimizer here.
On TikTok, the tanned youths are explaining why they no longer wear sunscreen. In one video, a young man films himself in the ocean while describing how you can naturally build up a "solar callus" or sun tolerance to getting burned. (You can't.) In another, a young woman confidently states that eating healthy foods full of polyphenols and other antioxidants will help make your body more resilient to sunburn. (Antioxidants help w …
MindOn demos shared intelligence, wherein humanoid robots delegate tasks to robotic arms, both trained on human centric data
![[SemiAnalysis] Stop Saying Half of 2026 US Datacenter Capacity Is Canceled](https://external-preview.redd.it/ROXwXi0TFPNvUrzKbIO-LYiRWJDA2zO1RAvO5aaffnQ.jpeg?width=640&crop=smart&auto=webp&s=6ead72531d689000e52d5fe4b339cb65fc2320be)
newsletter.semianalysis.com
SUMMARYSubquadratic emerged from stealth with a claimed mathematical breakthrough that could make large language models faster, cheaper, and far less energy-intensive by reducing transformer computations. Brain-computer interface trials are accelerating as more volunteers join studies, and China has become the first country to approve a BCI for medical use. One featured case is Casey Harrell, a man with ALS whose brain implant has helped him work, reconnect with loved ones, and read to his daughter.
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
A startup claims it broke through a bottleneck that’s holding back LLMs
AI startup Subquadratic came out of stealth last month with a huge claim: it had solved a mathematical bottleneck that had held back large language models for almost a decade.
The purported breakthrough comes from slashing the number of computations transformers need to carry out to generate answers. The result is a faster and cheaper LLM that uses far less energy than any other model on the market.
Many experts remained skeptical—but Subquadratic has started to share the receipts. They suggest that their approach might be worth paying attention to.
Here’s how the system works—and why some researchers still aren’t convinced.
—Will Douglas Heaven
Brain-computer interface trials are taking off
—Jessica Hamzelou
This week, I covered the story of Casey Harrell—a man with ALS who is “the first power user” of a brain implant. The device has enabled him to maintain an income, reconnect with friends and family, and read to his daughter. He told me that it’s “nothing short of revolutionary.”
Over the past couple of years, the number of BCI trial volunteers has soared. This year, China became the first country to approve a BCI for medical use. Advances in technology are allowing engineers to provide more features than ever. BCI research is properly taking off.
Find out how the technology is edging from the lab towards the market.
This story is from The Checkup, our weekly newsletter giving you the inside track on all things biotech. Sign up to receive it in your inbox every Thursday.
The must-reads
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1 Amazon workers who backed data center limits may face termination
The engineers say they’re under investigation by the company. (NYT $)
+ And could face discipline, including potential termination. (The Verge)
+They had testified at meetings about pausing data centers. (CNBC)
+ They’ve filed a joint complaint to Seattle’s Office for Civil Rights. (Wired $)
2 A new fossil discovery has rewritten 150 years of evolutionary theory
It suggests early land vertebrates skipped the tadpole stage. (New Scientist $)
+ And raises questions about how vertebrates adapted to land. (404 Media)
+ Sponges may have been the first animals. (MIT Technology Review)
3 Bernie Sanders plans to give the public direct ownership of AI firms
He’s unveiled new legislation to create an AI sovereign wealth fund. (AP News)
+ It would be funded through a one-time tax on AI companies’ stock. (Quartz)
+ And make annual payments directly to Americans. (Washington Post $)
4 Investors in China secretly acquired stakes in SpaceX before its IPO
One had ties to Chinese military contractors. (ProPublica)
+ The US fears China has got one of ASML’s top machines. (Reuters $)
5 Researchers have figured out Russia’s nuclear-powered missile
They call it “a terrible idea”—but not an impossible one. (NPR)
+ NASA is building a nuclear reactor-powered spacecraft. (MIT Technology Review)
6 Longevity medicine faces a do-or-die moment in a landmark trial
It will test whether cellular aging can be safely reversed in humans. (Axios)
+ The next step is “chemical reprogramming.” (MIT Technology Review)
7 Studies suggest AI may already be deskilling professionals
Over-reliance appears to weaken doctors’ and engineers’ abilities. (Nature)
8 Tech workers who maxed out their AI use are now trying to minimize it
Spiralling costs mean “tokenminning” has replaced “tokenmaxxing.” (NYT $)
9 Scientists say the human genome’s structure may confound AI models
Which would constrain AI-based models of biology and disease. (Quanta)
10 A new robotic self-driving toilet brings the bathroom to you
The Xiaoban also cleans up and empties itself all on its own. (The Verge)
Quote of the day
“They hated me. They were doing everything they could to knock me down. And look at them now.”
—Donald Trump mocks Mark Zuckerberg and Jeff Bezos in a conversation with Elon Musk that’s recounted in a new book, Wired reports.
One More Thing

PABLO DELCAN
Technology can help us feed the world, if we look beyond profit
The pandemic exposed the weak spots in our interconnected food system. They’re the result of decades’ worth of technological advances, from globe-spanning shipping to refrigeration networks. But technology is not inherently opposed to sustainable and resilient food systems.
Powerful technologies like genetic modification can create stronger local agriculture and a healthier food system—but they normally aren’t. The challenge is ensuring they serve food security and human well-being, rather than simply maximizing profits.
Dive into our food system’s problems and the solutions that technology can provide.
—Fabio Parasecoli
We can still have nice things
A place for comfort, fun, and distraction to brighten up your day. (Got any ideas? Drop me a line.)
+ This intriguing video tracks the covert reality of Japan’s shinobi.
+ Dive into this admirably obsessive archive covering over 100 different ways to tie your shoes.
+ One of the world’s largest digital collections of plants and fungi is now available for free to everyone.
+ A grand orchestra has beautifully covered Michael Jackson’s “Human Nature” at Abbey Road Studios.

Lukasz Larsson Warzecha/Getty Images
arstechnica.comMAJURO, Marshall Islands—Perched on the bow of an aluminum landing craft, Anne Cohen gazed a few yards ahead of the vessel toward a yellow robot gliding across the emerald Majuro lagoon.
The unmanned surface vehicle, called Yellowfin, was quickly becoming one of the coral researcher’s most dependable guides in these Central Pacific waters.
“She’s the best dive buddy,” said Cohen, a tenured scientist at the Woods Hole Oceanographic Institution in Cape Cod. Programmed to navigate to a precise set of coordinates, the robot cut through small swells like a tiny sailboat without a mast, directing Cohen toward a destination she had traveled thousands of miles to revisit.
SUMMARYNASA selected Relativity Space to build and launch Aeolus, a 2028 Mars orbiter designed to measure dust, winds, and atmospheric temperatures across the planet every day. The mission will use four instruments to give researchers and mission planners a global view of Mars’ atmosphere and improve conditions for future robotic and human landings. Relativity was founded in 2015 and later came under majority ownership by Eric Schmidt after funding difficulties.
NASA has selected Relativity Space to build and launch Aeolus, a 2028 Mars orbiter that would provide daily global measurements of dust, winds, and atmospheric temperatures to support future robotic and human missions. TechCrunch reports: The structure of the contract is akin to the deals that NASA made with SpaceX to fly cargo to the International Space Station, or Firefly Aerospace to put a lander on the Moon. The government agency handles the science, while the private company provides low-cost infrastructure. Aeolus, as the mission is dubbed, will contain four instruments to measure and image Mars from orbit, providing what NASA expects to be the first daily, global view of dust, winds, and temperature in its atmosphere. The agency said that data will make it safer for landers and, someday, astronauts, to visit the surface of the Red Planet.
By pairing NASA's world-class instruments with commercial innovation and investment, we can deliver more science, more often, and reduce the time it takes to get essential data into the hands of researchers preparing for future human missions to Mars," NASA administrator Jared Isaacman said in statement. The mission is set to launch in 2028 -- a rapid pace that will require Relativity to design and build the spacecraft to carry the Aeolus instruments, and finish building the rocket that will carry it to space, all on a tight timeline. NASA did not disclose how much it is paying Relativity for the mission, and Relativity did not respond to questions from TechCrunch.
Relativity was founded in 2015 by two former SpaceX and Blue Origin engineers, with the idea of using 3D printing to its maximum potential as a path to building a cheaper rocket. The company's first design, Terran-1, launched in March 2023 and failed mid-flight. Relativity doubled down by moving on to a larger design, dubbed the Terran R. Before Relativity could get it to the launch pad, the company ran into fundraising challenges, and Schmidt took a majority stake in the company in it last year, installing himself as CEO. He's been tight-lipped about the investment but has expressed interest in orbital data centers, and is thought to be using Relativity to launch a space telescope, Lazuili, financed by his family philanthropy, Schmidt Sciences.
SUMMARYMiami startup Subquadratic unveiled SubQ, an AI model it says uses sparse attention to cut the quadratic cost of transformer-based language models. Third-party tests from Appen found the model could be up to 56 times faster in a speed benchmark and reached 89.7% on LiveCodeBench, while handling context windows as large as 12 million tokens. The company says the system can process huge document sets more cheaply and quickly than competing models, though wider access is still limited.
Miami-based AI startup Subquadratic came out of stealth mode last month with a huge claim. It announced that it had solved a mathematical bottleneck that had been holding back large language models for almost a decade.
The details were thin, and many people were unconvinced. But Subquadratic has started to bring the receipts, sharing the results of an independent evaluation of its new tech. The results suggest that the company’s claims might be worth paying attention to.
According to Subquadratic, it has developed a new kind of LLM, called SubQ, that is faster and cheaper and uses a lot less energy than any other model on the market. The company also claims that SubQ is able to process up to 12 times as much text at once than most other models, allowing it to carry out a range of data-heavy tasks, such as analyzing hundreds of documents or entire code bases.
What’s more, Subquadratic says, SubQ does this while more or less matching the performance of the best models put out by Google DeepMind, OpenAI, and Anthropic on key tasks like coding.
The problem was that the company at first provided little evidence for its claims beyond a handful of self-published test scores. And it has yet to make SubQ widely available for people to try out themselves.
So it’s no surprise that Subquadratic’s claims were met with skepticism. Dan McAteer, an artificial intelligence engineer, captured the overall response on X: “SubQ is either the biggest breakthrough since the Transformer … or it’s AI Theranos.”
A month on, the company has published more information about its model, including the results of additional independent tests run by third-party firm Appen.
“We expected healthy skepticism,” says Subquadratic cofounder and chief technology officer Alex Whedon. “In hindsight, releasing the third-party benchmarks alongside the initial announcement would have preempted much of the skepticism, which is why we’re taking the time to make sure any future results are fully verified before putting them out.”
Subquadratic asked Appen, which evaluates other companies’ models, to run its tests on SubQ. The results seem to back up a lot of Subquadratic’s claims. “That was really exciting to me, it validated their architecture,” says Jeanine Sinanan-Singh, Appen’s director of generative AI research.
“I was like, ‘Wow, this could be a game changer,’ because models struggle with speed and inefficiency,” she adds. “But when you have kind of shocking results, it’s really not as credible when you say it yourself.”
SubQ won’t replace existing top models across the board, but it could offer huge increases in speed at a fraction of the typical cost for certain tasks. Subquadratic insists that in the long run, though, its breakthrough could change how LLMs are built. “We hope we’re kicking off a new age of efficiency,” says Justin Dangel, the firm’s cofounder and CEO. “We don’t think anybody will be building on transformers in a few years.”
Attention!
To understand why Subquadratic’s claims are a big deal, let’s dig into how most LLMs work. The key mechanism inside an LLM is a type of neural network called a transformer, which runs a process known as dense attention. Today’s LLMs typically chain together multiple transformers. (The foundational paper of the LLM era, published by researchers at Google in 2017, was titled “Attention Is All You Need.”)
Dense attention works like this: When a transformer processes a chunk of text, it first encodes each word (or part of a word, known as a token) with a number. To capture the meaning of the full text, it then multiplies each of those numbers with every other number for that text. For example, a piece of text 10,000 words long would kick off almost 50 million individual multiplications. That’s a lot of computation and the main reason that LLMs are notorious power hogs.
“If you want to summarize The Great Gatsby, you have to look at the first word and the last word together, and then you have to look at every other combination,” says Dangel.
As the length of the text increases, the number of computations skyrockets. That’s because each additional number must be multiplied by all other previous numbers. Double the number of words, and you roughly quadruple the number of computations, a rate of increase known as a quadratic expansion.
(You can picture this yourself: Draw a circle and mark dots around its edge. Each dot is a token. Then draw lines between pairs of dots to represent the multiplication of those two tokens. A circle with five dots will have 10 lines crossing it. Make it 10 dots and you will have 45 lines, 20 dots and you will have 190 lines, and so on.)
Slashing costs
Subquadratic’s solution is to ditch dense attention, the core operation of a transformer, in favor of what’s known as sparse attention, which slashes the number of computations needed. Instead of multiplying the number assigned to each token by every other number, sparse attention selects just some of the numbers to multiply. The idea is that not all relationships between words in a piece of text matter.
“Sparse attention says not all of those relationships are important, because they’re not,” says Whedon. “If you’re reading a book, you’re not going to look at the first and second words, first and third—that’s insane.”
It’s a simple approach, and Subquadratic is not the first to try it. “Pretty much everything under the sun has been attempted,” says Will Depue, an independent AI researcher who previously worked at OpenAI. “It’s not impossible, but it’s akin to running a four-minute mile.”
Previous techniques for selecting which numbers to multiply and which to ignore have not produced a mechanism that can capture the meaning of a document as well as dense attention can.
Subquadratic claims to have cracked the problem at last. It pitches SubQ as the first sparse-attention LLM that rivals mainstream dense-attention models in performance.
“Historically, most mechanisms have used fixed patterns, like always comparing the first word to the fifth,” says Whedon. “That’s pretty limiting. Language is too sophisticated for that. And so, one of the things that makes our mechanism unique is that we dynamically select which ones are important.”
The firm won’t say exactly how SubQ chooses which words to focus on, but the selection is calculated on the fly and differs for each piece of text the model is given. “That’s kind of where the secret sauce is,” says Whedon.
Testing, testing
The upshot is that for certain tasks, SubQ may be faster and cheaper to run than most other models. Appen evaluated SubQ on a handful of standard tests. In a straight-up speed test, which sets a baseline for how fast a model can operate in theory rather than assess what a model can actually do, Appen found that SubQ was 56 times faster than models using FlashAttention, a previous sparse-attention technique.
On LiveCodeBench, a test that looks at how well models perform on competitive coding problems taken from real contests, SubQ scored 89.7%, putting it in the same ballpark as other top coding models. “This model continues to provide frontier-level performance in coding,” says Appen’s Sinanan-Singh.
Subquadratic’s claims about cost are harder to verify because SubQ is not yet widely available. According to Dangel, it costs $2600 to run Anthropic’s LLM Opus 4.6 through RULER 128, a test developed by Nvidia to assess a model’s ability to retrieve information from large data sets. And SubQ? “It cost us eight dollars,” he says.
SubQ does seem to be able to handle very large data sets. The model has a context window (roughly akin to a working memory) up to 12 million tokens long. Most top models today have context windows one million tokens long. In a demo that Whedon ran for me, he asked SubQ to perform a task that required it to reason about information contained in 400 documents. It responded in seconds. When he gave Perplexity—a popular LLM-powered search engine—the same task, it failed to load all 400 documents.
Appen also ran the needle-in-a-haystack test, which assesses how well a model can retrieve specific information buried in a large amount of data. In its report, Appen states that SubQ scored 98% with context windows six million and 12 million tokens long, “sustaining near-perfect long-context retrieval at scales few models are tested at.”
Too good to be true?
Despite the high scores, benchmarks paint an incomplete picture of what a model can and cannot do. Testing under very specific conditions is not a substitute for running a model on a wide range of real tasks.
Subquadratic is offering SubQ as a model tailored to coding and to searching very large data sets. It says that tens of thousands of potential users have already signed up for early access, including more than 500 enterprise customers. But there’s a long waitlist, and the firm has given very few people access so far. Subquadratic’s response is that it is a new, small company with limited resources and cannot serve too many people at once.
Until more people get their hands on the model and try it out for themselves, some skepticism is justified. One nagging issue is that Subquadratic reused the weights (values set within a model during training that determine how it will behave) from a version of the Chinese open-source model Qwen to bootstrap SubQ, rather than training it from scratch. That’s a common thing for model makers to do, but it cuts across Subquadratic’s claim that it has fully reinvented how LLMs work.
“They may have built something real and useful,” says Depue. “But the public evidence does not yet justify the stronger claim that they have solved the quadratic attention bottleneck.”
In the meantime, Subquadratic cofounder Whedon insists that making something different was his only option. If you want to build a competitive model, you have to have new ideas, he says: “We’re more up against it than OpenAI is.”
 spectrum.ieee.org
spectrum.ieee.orgCharacter is the difference between a machine people tolerate and a product people trust
SUMMARYBrain-computer interface trials are expanding rapidly, with more volunteers, more companies, and new medical approvals in China. Casey Harrell, a man with ALS, has used a UC Davis brain implant since July 2023 to speak, browse the web, and work more independently, while researchers add features like privacy controls and profanity filtering. Academic and commercial teams, including BrainGate, Neuralink, Synchron, Neuracle, and Precision Neuroscience, are pushing BCIs from cursor control toward speech decoding.
This week, I covered the story of Casey Harrell—a man with ALS who is “the first power user” of a brain implant, according to the researchers who worked with him. Harrell is paralyzed and unable to speak coherently without the device. He has now spent almost three years using a brain-computer interface (BCI) that enables him to “speak,” surf the web, and perform his job as a climate activist, largely independently.
Since Harrell was implanted with the device, in July 2023, a team at the University of California, Davis, has worked with him to adjust and improve its offerings. They’ve refined its accuracy, for example. And they’ve introduced settings including a privacy mode and a “profanity filter” that lets Harrell talk to his daughter without risking accidental swearing.
Harrell told me that, for him, the device is “nothing short of revolutionary!” It has enabled him to maintain an income, reconnect with friends and family, and read to his daughter.
The team that developed his BCI is one of several working on ways to use technology to allow people with paralysis to communicate, engage with the online world, and regain some independence. And Harrell is one of a growing number of people volunteering their brains to, as he puts it, “pay it forward and do the scientific research … [and] get some personal benefit.”
Over the past couple of years, the number of BCI trial volunteers has soared. This year, China became the first country to approve a BCI for medical use. Advances in technology are allowing engineers to provide more features than ever. BCI research is properly taking off.
I should first point out that BCIs come in different forms. Harrell’s device includes a set of electrodes embedded in his brain that pick up the electrical activity associated with speech. Those electrodes are connected to two docking ports on top of his head that can be plugged into a computer.
That computer is loaded with software trained to decode his brain signals into phonemes (units of sound in speech) and predict what Harrell wants to say. He can then use an eye gaze tracker to make any corrections before the speech is played out loud.
But some BCIs don’t need to be “plugged in”—they’re fully implanted and wireless. Others are less invasive; they might involve placing wired electrodes on the surface of the brain or simply wearing a cap of electrodes, for example. There are trade-offs—the closer you get to the neurons you want to record from, the better your signal will be. But generally speaking, the more invasive the surgery, the higher the risk of complications.
BCIs can also have different functions. Harrell has ALS, but most BCIs in use today are sitting in the brains of people with spinal cord injuries. Typically, these individuals have some degree of paralysis; for example, they may be unable to move their arms and legs, but their face and ability to speak are unaffected. In those cases, BCIs can be used to control other kinds of devices that might help with mobility.
In 2024, Michelle Patrick-Krueger, then at the University of Houston, and her colleagues published a roundup of all trials of BCIs conducted between 1998, which is when they believe the first device was implanted, and the end of 2023. They identified 21 research groups that, among them, had trialed BCIs in a total of 67 volunteers.
“Since then, that number has increased a lot,” says Mariska Vansteensel, a BCI researcher at University Medical Center Utrecht. In January, Neuralink (the BCI company founded by trillionaire Elon Musk) announced that it has implanted 21 people with its device in the past two years.
Synchron, another BCI company, is currently testing its devices in trials in North America and Australia. Shanghai-based Neuracle has been trialing a BCI since November 2024, and it recently obtained approval for the device to be used outside of clinical trials. Precision Neuroscience, cofounded by a former co-creator of rival Neuralink, is also trialing its BCI, which sits on the surface of the brain.
At the same time, academic research has continued. The UC Davis team that worked with Harrell is part of BrainGate—a BCI research effort that has been running for the past two decades. Other academic teams are exploring a variety of devices, from the fully implanted to the minimally invasive.
Since 2024, when Patrick-Krueger’s paper was published, the number of people who have been implanted with a brain electrode has more than doubled, according to Vansteensel. “My current estimation would be around 150 people,” she says.
The technology is improving too. Take the BrainGate trial, for example. The first 17 years of that trial focused on the use of what researchers call “point-and-click” communication—allowing users to control a cursor and “click” with their brain activity. But in recent years the team has pivoted toward decoding speech, says David Brandman, the lead investigator on the team (and the person who implanted Harrell’s electrodes). Today, Harrell’s device uses a voice clone—the speech it produces is based on previous recordings of Harrell’s voice.
But BCIs are still experimental. And plenty of questions remain about who might benefit from them—and how long the devices will last. So far, most BCIs have been implanted in people with spinal cord injuries. We know even less about how they might benefit other people who have ALS, for example. In some cases where the devices initially helped people with ALS—even someone who was completely locked in—the BCIs eventually stopped working. And scientists don’t really know why.
The only way they’ll find out is through more research—and the participation of volunteers like Harrell. So it’s exciting to see trials truly take off. And I promise I’ll update you on where they stand two years from now.
This article first appeared in The Checkup, MIT Technology Review’s weekly biotech newsletter. To receive it in your inbox every Thursday, and read articles like this first, sign up here.

forbes.com
Loading more cached articles...